
最自然最直接的人机交互。

”移动互联网时代已经结束了,2016年到2017年是从移动互联网时代转向人工智能时代的转型阶段。PC互联网是人与计算机的交互,移动互联网是人与触摸屏的交互,到了人工智能时代,人机交互的方式会变成自然语言,带来很大变化。”——李彦宏

基本概念
一篇文章搞懂语音交互的来龙去脉
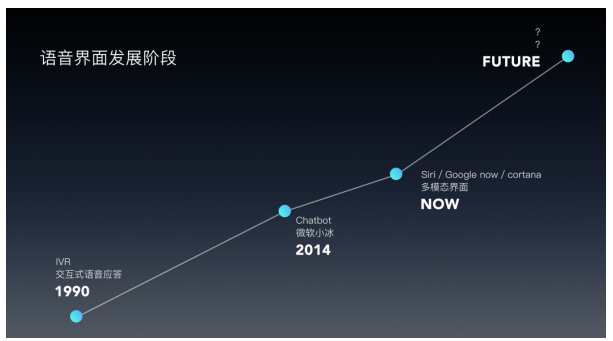
语音界面简史

在语音界面的设计中,vui应该注意什么?

在系统对人的语音理解方面分为两大类:asr:自动语言理解和nlu自然语言理解,目前的发展阶段已经到了自然语言理解的阶段。机器通过处理和理解文本,采用云处理的方式对用户语音进行识别和理解从而判断指令给出正确的反馈。
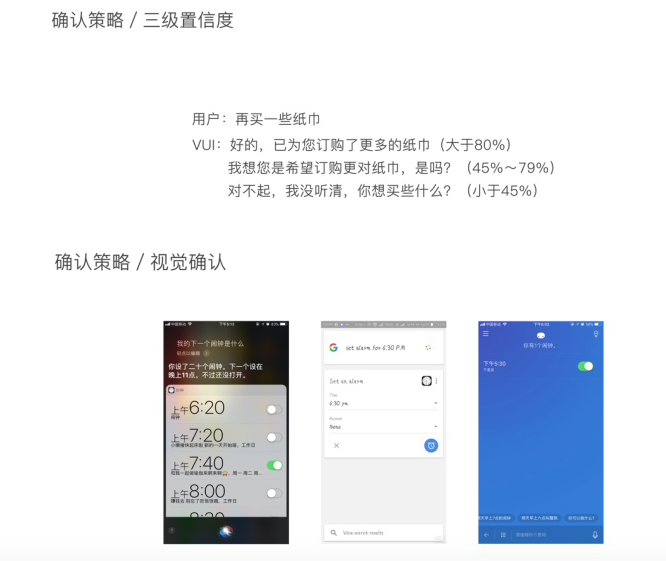
所有优秀的vui设计,都必须确保用户感觉到自己是被理解的,所以我们需要在设计原则中添加一个确认策略。确认策略的设计是因为在很多环境下机器并不能完全的识别用户所说的问题,同时在生活场景下,例如购物支付等场景,需要用户的再次确认,这个时候vui的确认策略就派上用场了。在设计确认策略的过程中我们需要了解几个问题:交互问答的错误后果是什么?系统需要什么样的方式怎么反馈?屏幕需要显示出什么?用户需要用什么样的手段进行确认等。

非语言的确认方式也就是行动反馈,不需要口头进行确认,例如假如正在创建一个语音控制灯光的系统,当你说打开灯光的时候,灯自然就会打开,此时已经给了你一个反馈,不需要进行语音进行提示了。在纯语音设备或者系统下,可以提供一个行为反馈,例如光效等。Vui系统在说话的时候,确认用户是否可以打断,现在一般的语音智能听到唤醒词才会停止说话,唤醒词应在本地处理,设备一直处于接收唤醒词的状态。多模态形式下,一般是不可以打断的,可以用可视化列表,如Siri不可以打断对话。




语音的发展趋势
例如上下文语意的理解,当然我们对siri说我想吃汉堡 它列出了几个附近的餐馆 ,当用户说好腻,不吃了,这个时候就需要系统理解上下文的语境从而给出正确的判断。
在消除歧义方面,当系统问用户,你的主要症状是什么?而用户说的是发烧和感冒,系统就要理解用户说的是两个症状,针对这个事情,系统需要进行回复两种不同的症状解决方式。
情感和情绪分析则需要机器进入强人工智能了,让机器理解人的情绪和情感从而给出对应的有情感的回答,不在是冷冰冰的机器,这永远是一个未来的发展方向。
对于高级自然语言的理解目前还处于初级阶段,目前,Siri和cortana出发处理问题的时候,会提供一个网页搜索,并不会直接回答你的问题,但高级自然语言理解可以听懂你说的话,直接回答。
深度解读|中国智能语音行业格局与未来发展趋势
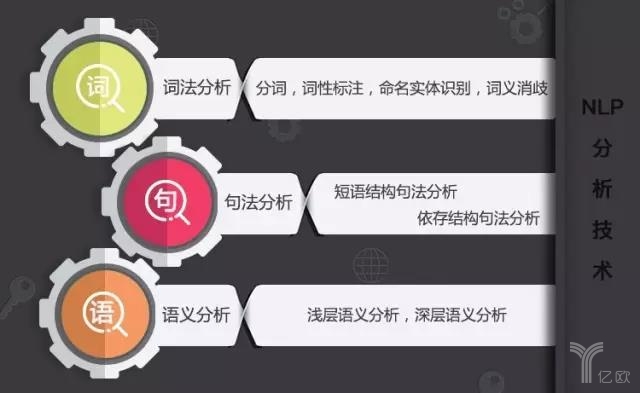
NLP技术大致包含三个层面:词法分析、句法分析、语义分析,三者之间既递进又相互包含。
事实案例
百度
凭借语音与对话技术的优势,百度在引领新一代人机交互平台上拥有巨大的机会,自然语言和其他智能交互方式有可能出现在从手机到家居的每一个设备中。为抓住这一机遇,百度决定成立度秘事业部,以加速百度人工智能战略布局及人工智能产品化和市场化进程。
百度高级总监景鲲和首席架构师朱凯华将担任事业部的核心管理层。景鲲担任事业部总经理,朱凯华担任事业部首席技术官。度秘业务直接向百度集团总裁和首席运营官陆奇汇报。
目前度秘已经具备7大类目、70+功能,并可广泛适用于手机、智能家居、智能穿戴和车载等场景下,通过语音交互的方式,满足用户所需。
百度首席科学家吴恩达表示2017年将是“对话机器”元年。通过自然语言进行语音对话的DuerOS,可以广泛支持智能硬件,并通过云端大脑时刻进化,是目前全球最“聪明”的对话式人工智能系统之一,也将成为百度在语音交互领域发力的有力抓手。
2016年,百度将人工智能提升为公司战略。
“移动互联网时代已经结束了,2016年到2017年是从移动互联网时代转向人工智能时代的转型阶段。PC互联网是人与计算机的交互,移动互联网是人与触摸屏的交互,到了人工智能时代,人机交互的方式会变成自然语言,带来很大变化。”——李彦宏

2015年11月是百度语音技术发展过程中的一个重要里程碑,它宣布其硅谷实验室已经开发出了一个强大的新型语音识别引擎,被称为深度语音识别系统(Deep Speech 2) 。它包含了一个非常大的、 “深”的神经网络,它学习了单词和短语的关联声音,引入了数以百万计的转录语音。Deep Speech 2在口语识别的准确度方面十分惊人。事实上,研究人员发现,有时它在识别汉语语音片段方面,要比人为识别更加准确。
百度的进步令人感到惊喜,因为普通话在发音方面十分复杂,并且音调不同,词和词意就不同。Deep Speech 2另一个引人注目的原因是,在加利福尼亚实验室研究这项技术的人员中,几乎没有人讲普通话、粤语、或其他任何中国方言。
该引擎基本上是一个通用的语音系统,如果输入足够多的示例,它同样可以进行英语的语音识别。
目前,百度搜索引擎听到的大部分声音命令都是比较简单的查询 – 例如,关于明天的天气或污染程度。对于这些问题的语音识别,该系统通常是非常准确的。然而,越来越多的用户开始问更加复杂的问题。面对这些情况,该公司在去年推出了自己的语音助手,作为其主要的移动应用程序的一部分,被称为度秘(DuEr) 。度秘可以帮助用户查询电影放映时间、或者是帮助用户在一家餐厅订位。
百度的最大挑战是使其人工智能系统,更为智能地理解和回应更加复杂的口语短语。最终,百度希望度秘可以进行有意义的来回对话,将变化的信息加入到讨论内容中。
为了实现这个目标,百度北京公司的一个研究小组正在努力提升口译用户进行查询所使用的系统。包括使用百度已应用于语音识别的神经网络技术,但也需要其他的技巧。百度已经聘请了一个团队来分析发送至度秘的查询内容,并纠正相关错误,从而不断提升该系统,使其越来越好用。
华为

由逾100名工程师组成的一个团队,在深圳开发语音助手服务,开发工作还处于早期阶段。华为语音助手项目目标宏大,瞄准苹果Siri、亚马逊Alexa和Alphabet谷歌助手,而非其他小角色。
语音助理大战,亚马逊Alexa、Google Assistant谁更胜一筹?
来源: DIGITIMES 发布者:DIGITIMES
时间:2018年5月30日 16:55
Google I/O 2018开发者大会5月上旬在美国旧金山举行,其中令人注目的产品是更新后的Google Assistant,不仅有更多声音选择,也让该产品更有互动沟通能力,这些更新后的强大功能无疑对Google Home、Home Mini与 Home Max智能音响的使用者来说是一大福音。不少人将Google Assistant与亚马逊(Amazon)的Alexa比较,Digital Trends网站便从声音、启动方式、设备相容性、儿童功能、通话等方面全盘比较两产品。
在声音方面,Google Assistant将会增加6种声音选项,加上原有的男声、女声,总共会有8种声音可以选择,其中新增知名歌手约翰传奇(John Legend)的真人配音,为其增添亮点。而Alexa目前只有女声,男声仅在加拿大测试时使用过,不过Alexa可以有不同口音选择,目前提供英国、加拿大以及印度腔调。
在启动对话方面,过去两产品都需要指定口令唤醒助理才能进行对话,Google Assistant舍弃了“Hey Google”的唤醒口令,推出了无间断对话功能,可自动判断使用者是接着上一个询问提出问题,并给出适当答案。Google宣布这项功能将在数周内启用。Alexa也在4月推出跟进模式(follow-up mode),让使用者在询问后的几秒内继续相关提问,这项功能仅会在某些应用程式(App)中被启用,不会在音乐播放或其他相似程式使用时被启动。
在设备相容性方面,Google宣布Google Assistant从原本能应用的1,000个家用智能设备增加到超过5,000个,不仅能使用在Google母公司Alphabet旗下监控设备Nest Cam、Nest Thermostat等,未来也能应用在August Smart Locks智能锁、飞利浦(Philips)旗下的Hue系列照明灯具,报导认为未来会有更多合作伙伴加入家用智能设备市场。而Alexa的相容性也有超过1.2万台家用智能设备,从智能门铃Ring Video Doorbell到Jenn-Air的智能家电都可使用,同时也能被运用在亚马逊旗下的Echo系列设备等。
在儿童功能方面,Google将推出“Pretty Please”功能,家长可要求儿童使用者以礼貌的语气与Google Assistant沟通,同时还会提供免费家庭游戏、活动以及如迪士尼(Disney)故事给家庭使用者。而Alexa日前也推出一款专门为孩童设计的智能音响Amazon Echo Dot Kids Edition,除了有不同颜色给使用者选择,也提供自动关机时间设定、玩游戏与说故事等专为孩童设计的功能。
在通话方面,Google Assistant与亚马逊Alexa都已有替使用者拨打电话的功能,也能透过扩音功能直接与电话另一端沟通。Google推出Duplex技术,让智能助理代表使用者进行电话沟通。在I/O大会上Google展示如何透过Duplex技术让Google Assistant帮忙订位,并于沟通时发出“嗯”与“呃”等思考语助词声音增加真实感,不过因为涉及道德议题,Google尚未说明该功能推出的具体时程。亚马逊Alexa目前没有如Duplex的功能,不过依照过往两大巨擘的竞争,外界猜测亚马逊未来也会推出不亚于此的功能。
AI口译官发展史
来源: 新电子 发布者:新电子
时间:2018年5月31日 04:47
在2018年的博鳌亚洲论坛中,除了主要议程外,最引人注目的热点是首次引进了人工智能进行会议中的即时口语翻译。然而,人工智能并没有出现原先大肆宣称的“让即时口译业界面对即将失业的威胁”,相反的,严重失误的翻译结果,反倒让即时口译从业人员松了口气,看来这行饭还可以吃很久。
《圣经. 旧约. 创世纪》第11章记载,在大洪水退去后,这世界上的人类都是诺亚的子孙,说同样的语言。那时人类开始合作,建造名为巴别塔的通天之塔。这个举动惊动了神,因此神让全世界的人类开始有了不同的语言,从此人类再也无法齐心合作。造通天塔的计划以失败告终,语言差异也成为了人类沟通时最大的障碍。也许是血液中仍有想要重建巴别塔的梦想,因此翻译就成为人类在过去千百年历史不断演进的重点文化工程。
语言的隔阂并不是那么容易打破的,尤其是要跨语言来理解同样的概念。人类历史上第一次出现跨语言的平行语料,是制作于公元前196年的罗赛塔石碑(Rosetta Stone),上面同时使用了古埃及文、古希腊文以及当地通俗文字,来记载古埃及国王托勒密五世登基的诏书。这也是翻译的重大里程碑。
基于规则的机器翻译
至于机器翻译的源头,可以追溯至1949年,资讯理论研究者Warren Weave正式提出了机器翻译的概念。五年后,也就是1954年,IBM与美国乔治敦大学合作公布了世界上第一台翻译机IBM-701。它能够将俄语翻译为英文,别看它有巨大的身躯,事实上它里面只内建了6条文法规则,以及250个单字。但即使如此,这仍是技术的重大突破,那时人类开始觉得应该很快就能将语言的高墙打破。
可能是神察觉有异,又对人类重建巴别塔的计划泼了一桶冷水。1964年,美国科学院成立了语言自动处理谘询委员会(Automatic Language Processing Advisory Committee, ALPAC)。两年后,在委员会提出的报告中认为机器翻译不值得继续投入,因为这份报告,造成接下来的十来年中,美国的机器翻译研究几乎完全停滞空白。
从IBM的第一台翻译机诞生到20世纪80年代,那时的技术主流都是基于规则的机器翻译。最常见的作法就是直接根据词典逐字翻译,虽然后来也有人倡议加入句法规则来修正。但是老实说,翻出来的结果都很令人沮丧,因为看起来蠢到极点。因此,到了80年代这样的作法就销声匿迹了。
为何语言没办法套用规则?因为语言是极其复杂且模糊的系统,从字的歧义到各种修辞,根本不可能穷举出所有规则。但有趣的是,不少近期投身于自然语言的新创公司,仍然企图用穷举规则来解决中文语义,但这种想法铁定会是以失败告终的。
我在这举个例子来说明为何规则是不可行的。先别提翻译在两个语言转换的复杂性,光是从中文来说,“快递送货很快”这样的概念你能想到多少种讲法?10种?还是100种?在我们之前做过的自然语言统计数据来看,一共可能会有3600种讲法,而且这个数字应该还会随时间增加。光一个概念如此简单的句子就能有那么复杂的规则体系,若用到翻译恐怕规则量会是个惊人的天文数字,因此基于规则的机器翻译思路就成为了昨日黄花。
基于实例的机器翻译
在全世界都陷入机器翻译低潮期,却有一个国家对于机器翻译有着强大的执念,那就是日本。日本人的英文能力差举世皆知,也因此对机器翻译有强烈的刚性需求。
日本京都大学的长尾真教授提出了基于实例的机器翻译,也就是别再去想让机器从无到有来翻译,我们只要存上足够多的例句,即使遇到不完全匹配的句子,我们也可以比对例句,只要替换不一样的词的翻译就可以。这种天真的想法当然没有比基于规则的机器翻译高明多少,所以并未引起风潮。但是没多久,人类重建巴别塔的希望似乎又重见曙光。
基于统计的机器翻译
引爆统计机器翻译热潮的还是IBM,在1993年发布的《机器翻译的数学理论》论文中提出了由五种以词为单位的统计模型,称为“IBM模型1”到“IBM模型5 ”。
统计模型的思路是把翻译当成机率问题。原则上是需要利用平行语料,然后逐字进行统计。例如,机器虽然不知道“知识”的英文是什么,但是在大多数的语料统计后,会发现只要有知识出现的句子,对应的英文例句就会出现“Knowledge”这个字。如此一来,即使不用人工维护词典与文法规则,也能让机器理解单词的意思。
这个概念并不新,因为最早Warren Weave就提出过类似的概念,只不过那时并没有足够的平行语料以及限于当时计算机的能力太弱,因此没有付诸实行。现代的统计机器翻译要从哪里去找来“现代的罗赛塔石碑”呢?最主要的来源其实是联合国,因为联合国的决议以及公告都会有各个会员国的语言版本,但除此之外,要自己制作平行语料,以现在人工翻译的成本换算一下就会知道这成本高到惊人。
在过去十来年,大家所熟悉的Google翻译都是基于统计机器翻译。听到这,应该大家就清楚统计翻译模型是无法成就通天塔大业的。在各位的印像中,机器翻译还只停留在“堪用”而非是“有用”的程度。
神经网络机器翻译
到了2014年,机器翻译迎来了史上最革命的改变——“深度学习”来了!
神经网络并不是新东西,事实上神经网络发明已经距今80多年了,但是自从2006年Geoffrey Hinton(深度学习三尊大神之首)改善了神经网络优化过于缓慢的致命缺点后,深度学习就不断地伴随各种奇迹似的成果频繁出现在我们的生活中。在2015年,机器首次实现图像识别超越人类;2016年,Alpha Go战胜世界棋王;2017年,语音识别超过人类速记员;2018年,机器英文阅读理解首次超越人类。当然机器翻译这个领域也因为有了深度学习这个超级肥料而开始枝繁叶茂。
深度学习三大神中的Yoshua Bengio在2014年的论文中,首次奠定了深度学习技术用于机器翻译的基本架构。他主要是使用基于序列的递归神经网络(RNN),让机器可以自动捕捉句子间的单词特征,进而能够自动书写为另一种语言的翻译结果。此文一出,Google如获至宝。很快地,在Google供应充足火药以及大神的加持之下,Google于2016年正式宣布将所有统计机器翻译下架,神经网络机器翻译上位,成为现代机器翻译的绝对主流。
Google的神经网络机器翻译最大的特色是加入了注意力机制(Attention),注意力机制其实就是在模拟人类翻译时,会先用眼睛扫过一遍,然后会挑出几个重点字来确认语义的过程(图2)。果然有了注意力机制加持后威力大增。Google宣称,在“英—法”,“英—中”,“英—西”等多个语对中,错误率跟之前的统计机器翻译系统相比降低了60%。
神经网络虽然可以根据现有的平行语料学习,理解句中细微的语言特征,但是它并非完美无缺,最大的问题来自于需要大量的语料以及它如黑盒子般的难以理解。也就是说,就算出了错也无从改起,只能够供应更多的正确语料来让“深度学习”改正。也因此同样一个句型,却可以有截然不同的翻译结果。
2018年2月,微软(Microsoft)让机器语言理解超越人类后马上又有新举措。3月14日,微软亚洲研究院与雷德蒙研究院的研究人员宣布,其研发的机器翻译系统在通用新闻报导测试集Newstest2017的中英翻译测试集上,达到了可与人工翻译媲美的水平。这自然是神经网络机器翻译的一大胜利,当然在架构上也有了不少创新,其中最值得注意的是加入了对偶学习(Dual Learning)以及推敲网络(Deliberation Networks)。
对偶学习要解决平行语料有限的问题,一般来说深度学习必须同时要提供给机器答案,这样机器才能够根据它的翻译结果与答案间的差异持续修正改进。至于推敲网络也是模仿人类翻译的过程,通常人工翻译会先做一次粗略的翻译,然后再将内容调整为精确的二次翻译结果,其实各位可以发现不管再聪明的神经网络,最终仍要参考地表上最聪明的生物,也就是身为人类的我们。
语言无法脱离使用情境
机器翻译的发展并不意味着未来翻译界人士将会没有饭吃了。可以注意到的是,微软发表会曾强调“通用新闻报导测试集Newstest2017”的“中英翻译测试集”上,数据集表现好未必能与通用性划上等号,这也就可以说明为何腾讯翻译君明明平常口碑不错,但是为何在博鳌即时口译却表现失准。
即时口译可说是翻译任务的顶点,除了要有正确听力理解原句,还要在有限时间内转换为其他语言。而且别忘了讲者不会给翻译任何等待的时间,所以等于语音识别与机器翻译必须同步处理,再加上现场杂音、讲者的表达方式、语气词感叹词等等干扰因素,都有可能会造成机器的误判。
就我看来,腾讯翻译君,可被指责的点可能只是不够用功,没有把关键的专有名词录入,这才会发生“一条公路和一条腰带”这种“经典错误”。
从图3也可以看到一个有趣的差异,为何西方机器翻译错得离谱,但是本国的机器翻译却几乎都能掌握原意?这是因为语言不能脱离人类的使用场景而存在。即我们语文学习中常强调的上下文(Context),这来自于我们过去的文化、过去共有的记忆所构成的。没读过唐诗的Google自然无法理解这句诗的精髓。语言会是人工智能时代人类最后的壁垒,因为语言会因人类的使用不断地发生变化,这是机器很难完美替代的。
随着技术进步,终有一天,机器翻译会从“堪用”变成“有用”,再进化至“好用”。但如同我一直以来的论点,机器不会抢了人类的工作,能让人类失业的其实只有我们自己。如何善用人工智能成为自己的工具,把自己从无聊繁琐的工作中抽身,这才是面对未来的正确姿势。
Kaldi
Kaldi是一个用C++ 编写的语音识别工具包,在Apache License v2.0下授权。Kaldi目的在于语音识别研究人员使用。据传说,Kaldi是发现咖啡厂的埃塞俄比亚旅行者。
解析深度学习:语音识别实践

目录
译者序 iv
序 vii
前言 ix
术语缩写 xxii
符号 xxvii
第 1 章 简介 1
1.1 自动语音识别:更好的沟通之桥 . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 人类之间的交流 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.2 人机交流 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 语音识别系统的基本结构 . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 全书结构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3.1 第一部分:传统声学模型 . . . . . . . . . . . . . . . . . . . . . . 6
1.3.2 第二部分:深度神经网络 . . . . . . . . . . . . . . . . . . . . . . 6
1.3.3 第三部分:语音识别中的 DNN-HMM 混合系统 . . . . . . . . . . 7
1.3.4 第四部分:深度神经网络中的表征学习 . . . . . . . . . . . . . . 7
1.3.5 第五部分:高级的深度模型 . . . . . . . . . . . . . . . . . . . . . 7
第一部分 传统声学模型 9
第 2 章 混合高斯模型 11
2.1 随机变量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.2 高斯分布和混合高斯随机变量 . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 参数估计 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 采用混合高斯分布对语音特征建模 . . . . . . . . . . . . . . . . . . . . . 16
第 3 章 隐马尔可夫模型及其变体 19
3.1 介绍 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 马尔可夫链 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3 序列与模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3.1 隐马尔可夫模型的性质 . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3.2 隐马尔可夫模型的仿真 . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3.3 隐马尔可夫模型似然度的计算 . . . . . . . . . . . . . . . . . . . . 24
3.3.4 计算似然度的高效算法 . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.5 前向与后向递归式的证明 . . . . . . . . . . . . . . . . . . . . . . 27
3.4 期望最大化算法及其在学习 HMM 参数中的应用 . . . . . . . . . . . . . 28
3.4.1 期望最大化算法介绍 . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4.2 使用 EM 算法来学习 HMM 参数——Baum-Welch 算法 . . . . . . 30
3.5 用于解码 HMM 状态序列的维特比算法 . . . . . . . . . . . . . . . . . . . 34
3.5.1 动态规划和维特比算法 . . . . . . . . . . . . . . . . . . . . . . . . 34
3.5.2 用于解码 HMM 状态的动态规划算法 . . . . . . . . . . . . . . . . 35
3.6 隐马尔可夫模型和生成语音识别模型的变体 . . . . . . . . . . . . . . . . 37
3.6.1 用于语音识别的 GMM-HMM 模型 . . . . . . . . . . . . . . . . . 38
3.6.2 基于轨迹和隐藏动态模型的语音建模和识别 . . . . . . . . . . . . 39
3.6.3 使用生成模型 HMM 及其变体解决语音识别问题 . . . . . . . . . 40
第二部分 深度神经网络 43
第 4 章 深度神经网络 45
4.1 深度神经网络框架 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2 使用误差反向传播来进行参数训练 . . . . . . . . . . . . . . . . . . . . . 48
4.2.1 训练准则 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.2.2 训练算法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.3 实际应用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.3.1 数据预处理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.3.2 模型初始化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3.3 权重衰减 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3.4 丢弃法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.3.5 批量块大小的选择 . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.3.6 取样随机化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.3.7 惯性系数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.3.8 学习率和停止准则 . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.3.9 网络结构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.3.10 可复现性与可重启性 . . . . . . . . . . . . . . . . . . . . . . . . . 62
第 5 章 高级模型初始化技术 65
5.1 受限玻尔兹曼机 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.1.1 受限玻尔兹曼机的属性 . . . . . . . . . . . . . . . . . . . . . . . . 67
5.1.2 受限玻尔兹曼机参数学习 . . . . . . . . . . . . . . . . . . . . . . 70
5.2 深度置信网络预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.3 降噪自动编码器预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
5.4 鉴别性预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.5 混合预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
5.6 采用丢弃法的预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
第三部分 语音识别中的深度神经网络–隐马尔可夫混合模型 81
第 6 章 深度神经网络–隐马尔可夫模型混合系统 83
6.1 DNN-HMM 混合系统 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.1.1 结构 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
6.1.2 用 CD-DNN-HMM 解码 . . . . . . . . . . . . . . . . . . . . . . . . 85
6.1.3 CD-DNN-HMM 训练过程 . . . . . . . . . . . . . . . . . . . . . . . 86
6.1.4 上下文窗口的影响 . . . . . . . . . . . . . . . . . . . . . . . . . . 88
6.2 CD-DNN-HMM 的关键模块及分析 . . . . . . . . . . . . . . . . . . . . . 90
6.2.1 进行比较和分析的数据集和实验 . . . . . . . . . . . . . . . . . . 90
6.2.2 对单音素或者三音素的状态进行建模 . . . . . . . . . . . . . . . . 92
6.2.3 越深越好 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
6.2.4 利用相邻的语音帧 . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.2.5 预训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
6.2.6 训练数据的标注质量的影响 . . . . . . . . . . . . . . . . . . . . . 95
6.2.7 调整转移概率 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.3 基于 KL 距离的隐马尔可夫模型 . . . . . . . . . . . . . . . . . . . . . . . 96
第 7 章 训练和解码的加速 99
7.1 训练加速 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
7.1.1 使用多 GPU 流水线反向传播 . . . . . . . . . . . . . . . . . . . . 100
7.1.2 异步随机梯度下降 . . . . . . . . . . . . . . . . . . . . . . . . . . 103
7.1.3 增广拉格朗日算法及乘子方向交替算法 . . . . . . . . . . . . . . 106
7.1.4 减小模型规模 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 107
7.1.5 其他方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
7.2 加速解码 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7.2.1 并行计算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
7.2.2 稀疏网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
7.2.3 低秩近似 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113
7.2.4 用大尺寸 DNN 训练小尺寸 DNN . . . . . . . . . . . . . . . . . . 114
7.2.5 多帧 DNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115
第 8 章 深度神经网络序列鉴别性训练 117
8.1 序列鉴别性训练准则 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
8.1.1 最大相互信息 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 118
8.1.2 增强型 MMI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
8.1.3 最小音素错误/状态级最小贝叶斯风险 . . . . . . . . . . . . . . . 120
8.1.4 统一的公式 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
8.2 具体实现中的考量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
8.2.1 词图产生 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
8.2.2 词图补偿 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
8.2.3 帧平滑 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8.2.4 学习率调整 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 125
8.2.5 训练准则选择 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
8.2.6 其他考量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
8.3 噪声对比估计 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
8.3.1 将概率密度估计问题转换为二分类设计问题 . . . . . . . . . . . . 127
8.3.2 拓展到未归一化的模型 . . . . . . . . . . . . . . . . . . . . . . . . 129
8.3.3 在深度学习网络训练中应用噪声对比估计算法 . . . . . . . . . . 130
第四部分 深度神经网络中的特征表示学习 133
第 9 章 深度神经网络中的特征表示学习 135
9.1 特征和分类器的联合学习 . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
9.2 特征层级 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 136
9.3 使用随意输入特征的灵活性 . . . . . . . . . . . . . . . . . . . . . . . . . 140
9.4 特征的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
9.4.1 对说话人变化的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . 141
9.4.2 对环境变化的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . . 142
9.5 对环境的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
9.5.1 对噪声的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
9.5.2 对语速变化的鲁棒性 . . . . . . . . . . . . . . . . . . . . . . . . . 147
9.6 缺乏严重信号失真情况下的推广能力 . . . . . . . . . . . . . . . . . . . . 148
第 10 章 深度神经网络和混合高斯模型的融合 151
10.1 在 GMM-HMM 系统中使用由 DNN 衍生的特征 . . . . . . . . . . . . . . 151
10.1.1 使用 Tandem 和瓶颈特征的 GMM-HMM 模型 . . . . . . . . . . . 151
10.1.2 DNN-HMM 混合系统与采用深度特征的 GMM-HMM 系统的比较 154
10.2 识别结果融合技术 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156
10.2.1 识别错误票选降低技术( ROVER) . . . . . . . . . . . . . . . . . 157
10.2.2 分段条件随机场( SCARF) . . . . . . . . . . . . . . . . . . . . . 159
10.2.3 最小贝叶斯风险词图融合 . . . . . . . . . . . . . . . . . . . . . . 160
10.3 帧级别的声学分数融合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
10.4 多流语音识别 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161
第 11 章 深度神经网络的自适应技术 165
11.1 深度神经网络中的自适应问题 . . . . . . . . . . . . . . . . . . . . . . . . 165
11.2 线性变换 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
11.2.1 线性输入网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
11.2.2 线性输出网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
11.3 线性隐层网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
11.4 保守训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
11.4.1 L 2 正则项 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
11.4.2 KL 距离正则项 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
11.4.3 减少每个说话人的模型开销 . . . . . . . . . . . . . . . . . . . . . 173
11.5 子空间方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
11.5.1 通过主成分分析构建子空间 . . . . . . . . . . . . . . . . . . . . . 175
11.5.2 噪声感知、说话人感知及设备感知训练 . . . . . . . . . . . . . . 176
11.5.3 张量 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
11.6 DNN 说话人自适应的效果 . . . . . . . . . . . . . . . . . . . . . . . . . . 181
11.6.1 基于 KL 距离的正则化方法 . . . . . . . . . . . . . . . . . . . . . 181
11.6.2 说话人感知训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
第五部分 先进的深度学习模型 185
第 12 章 深度神经网络中的表征共享和迁移 187
12.1 多任务和迁移学习 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
12.1.1 多任务学习 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
12.1.2 迁移学习 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
12.2 多语言和跨语言语音识别 . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
12.2.1 基于 Tandem 或瓶颈特征的跨语言语音识别 . . . . . . . . . . . . 190
12.2.2 共享隐层的多语言深度神经网络 . . . . . . . . . . . . . . . . . . 191
12.2.3 跨语言模型迁移 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
12.3 语音识别中深度神经网络的多目标学习 . . . . . . . . . . . . . . . . . . . 197
12.3.1 使用多任务学习的鲁棒语音识别 . . . . . . . . . . . . . . . . . . 197
12.3.2 使用多任务学习改善音素识别 . . . . . . . . . . . . . . . . . . . . 198
12.3.3 同时识别音素和字素( graphemes) . . . . . . . . . . . . . . . . . 199
12.4 使用视听信息的鲁棒语音识别 . . . . . . . . . . . . . . . . . . . . . . . . 199
第 13 章 循环神经网络及相关模型 201
13.1 介绍 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
13.2 基本循环神经网络中的状态-空间公式 . . . . . . . . . . . . . . . . . . . . 203
13.3 沿时反向传播学习算法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
13.3.1 最小化目标函数 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
13.3.2 误差项的递归计算 . . . . . . . . . . . . . . . . . . . . . . . . . . 205
13.3.3 循环神经网络权重的更新 . . . . . . . . . . . . . . . . . . . . . . 206
13.4 一种用于学习循环神经网络的原始对偶技术 . . . . . . . . . . . . . . . . 208
13.4.1 循环神经网络学习的难点 . . . . . . . . . . . . . . . . . . . . . . 208
13.4.2 回声状态( Echo-State)性质及其充分条件 . . . . . . . . . . . . . 208
13.4.3 将循环神经网络的学习转化为带约束的优化问题 . . . . . . . . . 209
13.4.4 一种用于学习 RNN 的原始对偶方法 . . . . . . . . . . . . . . . . 210
13.5 结合长短时记忆单元( LSTM)的循环神经网络 . . . . . . . . . . . . . . 212
13.5.1 动机与应用 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212
13.5.2 长短时记忆单元的神经元架构 . . . . . . . . . . . . . . . . . . . . 213
13.5.3 LSTM-RNN 的训练 . . . . . . . . . . . . . . . . . . . . . . . . . . 214
13.6 循环神经网络的对比分析 . . . . . . . . . . . . . . . . . . . . . . . . . . . 214
13.6.1 信息流方向的对比:自上而下还是自下而上 . . . . . . . . . . . . 215
13.6.2 信息表征的对比:集中式还是分布式 . . . . . . . . . . . . . . . . 217
13.6.3 解释能力的对比:隐含层推断还是端到端学习 . . . . . . . . . . 218
13.6.4 参数化方式的对比:吝啬参数集合还是大规模参数矩阵 . . . . . 218
13.6.5 模型学习方法的对比:变分推理还是梯度下降 . . . . . . . . . . 219
13.6.6 识别正确率的比较 . . . . . . . . . . . . . . . . . . . . . . . . . . 220
13.7 讨论 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
第 14 章 计算型网络 223
14.1 计算型网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
14.2 前向计算 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224
14.3 模型训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
14.4 典型的计算节点 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
14.4.1 无操作数的计算节点 . . . . . . . . . . . . . . . . . . . . . . . . . 232
14.4.2 含一个操作数的计算节点 . . . . . . . . . . . . . . . . . . . . . . 232
14.4.3 含两个操作数的计算节点 . . . . . . . . . . . . . . . . . . . . . . 237
14.4.4 用来计算统计量的计算节点类型 . . . . . . . . . . . . . . . . . . 244
14.5 卷积神经网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 245
14.6 循环连接 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 248
14.6.1 只在循环中一个接一个地处理样本 . . . . . . . . . . . . . . . . . 249
14.6.2 同时处理多个句子 . . . . . . . . . . . . . . . . . . . . . . . . . . 251
14.6.3 创建任意的循环神经网络 . . . . . . . . . . . . . . . . . . . . . . 252
第 15 章 总结及未来研究方向 255
15.1 路线图 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 255
15.1.1 语音识别中的深度神经网络启蒙 . . . . . . . . . . . . . . . . . . 255
15.1.2 深度神经网络训练和解码加速 . . . . . . . . . . . . . . . . . . . . 258
15.1.3 序列鉴别性训练 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 258
15.1.4 特征处理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 259
15.1.5 自适应 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 260
15.1.6 多任务和迁移学习 . . . . . . . . . . . . . . . . . . . . . . . . . . 261
15.1.7 卷积神经网络 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261
15.1.8 循环神经网络和长短时记忆神经网络 . . . . . . . . . . . . . . . . 261
15.1.9 其他深度模型 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
15.2 技术前沿和未来方向 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
15.2.1 技术前沿简析 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
15.2.2 未来方向 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 263
参考文献 267
![]()
Kaldi中文手册
2018.06.14–一步一步地将其吃透
Kaldi在Window上的安装
Cygwin下安装Kaldi
解决Cygwin “error while loading shared libraries”的问题
当前位置:找DLL下载站 → DLL下载 → C → cygmpfr-4.dll
1 - 关于Kaldi项目
Kaldi官方文档(中文版) - Kaldi教程
Kaldi官方文档(中文版) - 数据准备
Kaldi 模型训练与测试流程
拷贝一下Docker中Kaldi for android编译步骤,手动编译也可以参照此步骤
An Android app that offers speech-to-text services to other apps
Kaldi gstreamer android client
DFSMN在阿里巴巴的应用以及如何采用开源代码训练DFSMN模型
Virtual Box

VirtualBox 是一款开源虚拟机软件。VirtualBox 是由德国 Innotek 公司开发,由Sun Microsystems公司出品的软件,使用Qt编写,在 Sun 被 Oracle 收购后正式更名成 Oracle VM VirtualBox。Innotek 以 GNU General Public License (GPL) 释出 VirtualBox,并提供二进制版本及 OSE 版本的代码。使用者可以在VirtualBox上安装并且执行Solaris、Windows、DOS、Linux、OS/2 Warp、BSD等系统作为客户端操作系统。现在则由甲骨文公司进行开发,是甲骨文公司xVM虚拟化平台技术的一部份。
VirtualBox号称是最强的免费虚拟机软件,它不仅具有丰富的特色,而且性能也很优异!它简单易用,可虚拟的系统包括Windows(从Windows 3.1到Windows10、Windows Server 2012,所有的Windows系统都支持)、Mac OS X、Linux、OpenBSD、Solaris、IBM OS2甚至Android等操作系统!使用者可以在VirtualBox上安装并且运行上述的这些操作系统! 与同性质的VMware及Virtual PC比较下,VirtualBox独到之处包括远端桌面协定(RDP)、iSCSI及USB的支持,VirtualBox在客户端操作系统上已可以支持USB 2.0的硬件装置,不过要安装 VirtualBox Extension Pack。
基于VirtualBox虚拟机安装Ubuntu图文教程
VMWare

VMware总部位于美国加州帕洛阿尔托 ,是全球云基础架构和移动商务解决方案厂商,提供基于VMware的解决方案,企业通过数据中心改造和公有云整合业务,借助企业安全转型维系客户信任,实现任意云端和设备上运行、管理、连接及保护任意应用 。
下载 VMware Workstation Pro
VMware Workstation 14 Pro 安装和激活
VMware Workstation 14 Pro安装与激活
CG54H-D8D0H-H8DHY-C6X7X-N2KG6
ZC3WK-AFXEK-488JP-A7MQX-XL8YF
AC5XK-0ZD4H-088HP-9NQZV-ZG2R4
ZC5XK-A6E0M-080XQ-04ZZG-YF08D
ZY5H0-D3Y8K-M89EZ-AYPEG-MYUA8
VMware Workstation 14 Pro for Windows:
CG54H-D8D0H-H8DHY-C6X7X-N2KG6
ZC3WK-AFXEK-488JP-A7MQX-XL8YF
AC5XK-0ZD4H-088HP-9NQZV-ZG2R4
ZC5XK-A6E0M-080XQ-04ZZG-YF08D
ZY5H0-D3Y8K-M89EZ-AYPEG-MYUA8
VMware Workstation 12 Pro for Windows :
5A02H-AU243-TZJ49-GTC7K-3C61N
VF5XA-FNDDJ-085GZ-4NXZ9-N20E6
UC5MR-8NE16-H81WY-R7QGV-QG2D8
ZG1WH-ATY96-H80QP-X7PEX-Y30V4
AA3E0-0VDE1-0893Z-KGZ59-QGAVF
如何安装和使用VMware Workstation 虚拟机
Ubuntu

Ubuntu(友帮拓、优般图、乌班图)是一个以桌面应用为主的开源GNU/Linux操作系统,Ubuntu 是基于Debian GNU/Linux,支持x86、amd64(即x64)和ppc架构,由全球化的专业开发团队(Canonical Ltd)打造的。 其名称来自非洲南部祖鲁语或豪萨语的“ubuntu”一词 ,类似儒家“仁爱”的思想,意思是“人性”、“我的存在是因为大家的存在”,是非洲传统的一种价值观。